
Last Sunday, the Deep Learning community, especially those using PyTorch and NumPy, were hit by a Reddit post and a follow up tweet by Andrej Karpathy, Senior Director of AI at Tesla:
Using PyTorch + NumPy? A bug that plagues thousands of open-source ML projects https://reddit.com/r/MachineLearning/comments/mocpgj/p_using_pytorch_numpy_a_bug_that_plagues/ hah yes, a favorite super common super subtle bug Bug. Bugs in deep learning silently make results slightly worse, pays to be v distrusting & defensive: https://karpathy.github.io/2019/04/25/recipe/
— Andrej Karpathy (@karpathy) April 11, 2021
In this post, my goal is to delve a little deeper into the identified issue and give some input on why I think this is not a bug, but a feature.
In the mentioned Reddit post, Tanel Pärnamaa, discusses how using NumPy’s random number generator with multi-process data loading in PyTorch produces identical augmentations, unless you take care of it by setting the random seeds of the workers in the DataLoader. Tanel claims that after analyzing thousands of repos using custom datasets on PyTorch, the vast majority of them are not aware of this issue and have in fact fallen in the trap. Such repos include PyTorch official tutorial and code from companies like OpenAI or NVIDIA, and gives a few real examples showing that this happens. As a reference, Tanel gives an example of duplicated random crop augmentations when you follow PyTorch official tutorial on custom datasets:
 Image credit: Tanel Pärnamaa
Image credit: Tanel Pärnamaa
This can’t be true - was my first thought
Random number generators can be tricky and adding parallel workers to the mix makes it even more challenging, having to deal with independent streams. How do you know that the Random Number Generators in different workers are in fact statistically independent? Well, there has been a lot of research on this field and various schemes and algorithms may be used. Reproducibility is important when developing and debugging and independence needed for correctness. Parallel Random Number Generation in NumPy seems to be reasonably well documented. So, the problem didn’t seem to be there.
Let’s look then into PyTorch DataLoader’s implementation. Going through the PyTorch documentation, this also seems to be right and warns how using libraries such as NumPy may cause each worker to return identical random numbers:
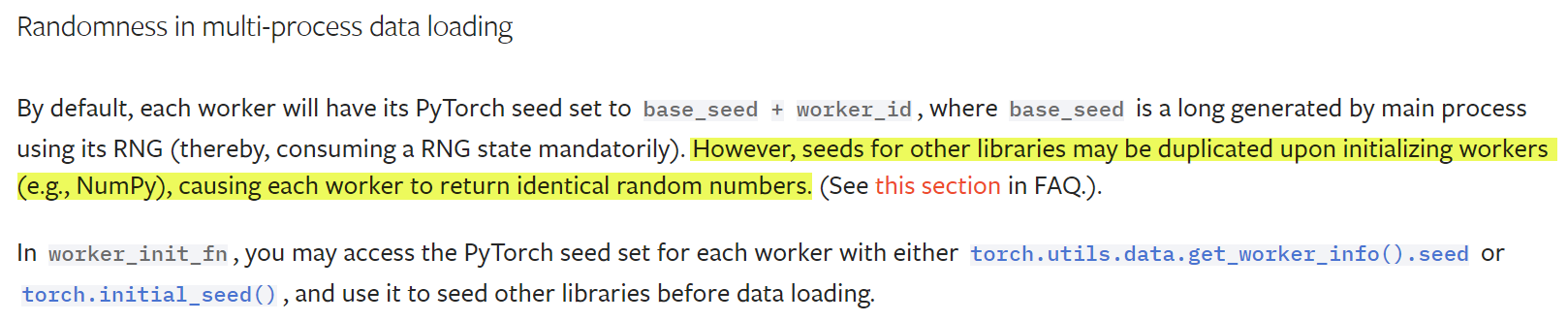
In fact, it is stated clearly in the FAQ and gives detail on how to properly set up random seeds in the workers using worker_init_fn:

So, going back to the question: is this a bug? No, this is the expected behavior by design.
Next question. Is this what users expect for the software to do? Well, according to the references pointed out in the Reddit post, and all controversy, apparently not. The software, as my British friends would say, does what it says on the tin. But it seems that the specification and design of DataLoader is not aligned with the expected use from the community.
Will DataLoader’s implementation change? Maybe, maybe not. Let’s keep an eye on the GitHub issue to see where this goes…
As a final note, I can’t help it but leave here one of my favorite Dilbert’s comic strips:




Comments